MPI essential
问题描述
MPI,即“Message Passing Interface”,信息传递接口,作为高性能计算绕不开的跨平台通讯协议,广泛地应用在科学计算的项目中。本文旨在以实践为目的介绍通过MPI实现并行计算的基本方式以及MPI应用于并行计算的核心思路。
主要参考MPItutorial[1]和mpi4py[2] 的内容,实例以python为主要介绍,代码来自于mpi4py。
开始并行计算
一般运行并行程序或者脚本,在linux和windows平台分别有
1 | |
这里进程数是编程人员人为规定的,它依据计算程序并行任务实际需求而定。
一些容易混淆的概念
在处理并行计算的过程中,初学者容易对并行计算的一些概念产生误解,这里做简要解释。
进程(process)和线程(thread)

我们日常使用计算机最常遇到就是任务进程的概念,容易理解的是,计算机处理数据的过程也和人类似,需要将具体任务拆分为若干子集合,然后分别完成。这里一个任务对应一个进程,而子集合的处理则对应计算机处理线程的划分。由于,CPU物理架构的限制,一个物理核心所集成的多级缓存只能同时容纳一个线程的任务数据,故而CPU一个物理核心只能同时处理一个任务进程,这里同时的概念就涉及了并行和并发的区分。
并行(parallel)和并发(concurrent)

并行与并发
并行概念的核心是同时(synchronization),而多个物理核心的CPU如图右所示同时处理对应多个进程实现的是并行,否则为并发。一个容易引起误解的概念是超线程(multithreads)。
Intel的CPU因为具有超线程技术,即存在所谓虚拟的核心,实际上超线程技术是一种多线程处理的优化策略,不能认为一个4核8线程的处理器可以并行处理8个进程,按照之前的理解,它只能4核并行。事实上,计算机在处理任务进程时可以通过协调各进程的线程树实现高效的数据处理,实现1+1>2的处理效率,这是线程优化的结果。

基础框架
三种语言版本的比较
C\C++
1 | |
Fortran
1 | |
Python
1 | |
C和Fortran作为编译型语言,在实现MPI的语法上具有类似的形式,其中MPI_Init和MPI_Finalize分别是初始化通信接口的环境和结束环境,并且函数的调用并没有返回值。而Python作为脚本型语言,是以函数返回值的形式获取MPI的参数,并不需要初始化(MPI_Init)\终止(MPI_Finalize) MPI环境的函数,形式上更简洁一些,但基础部件大同小异,MPI在Python上的组件和属性详细内容可以参看mpi4py.MPI。另外,在C和Fortran中需要额外调用mpi.h这个标准库文件。
进程间点对点通信(point-to-point communication)
MPI_Recv&MPI_Send
根据上节对进程的描述,进程可以类比现实生活中的邮箱,邮箱的功能就是信件的收发,而通俗地讲,进程就是包含一系列计算机待处理任务的一个集合。所以MPI点对点通信实现的就是两个进程间的信息收发,也就是所谓通信(下图所示)。点对点通信是MPI的基础功能。

以C为例,MPI点对点通信两个重要的组件是
1 | |
即收发组件。
这里MPI_Recv组件的参数“data”即进程需要收发的数据,“count”则是对应“data”的数量,“datatype”是收发数据的数据类型(见下表)。“source”是一个整型数据,即对于接收信息的进程而言,它就是指发送该信息进程的ID,和MPI_Send的“destination”相对。“communicator”即通信域或通讯器,一般在C或者Fortran中有关键字“MPI_Comm_World”,如上文提到的,它包含了初始化MPI环境中所有的进程,与之对应,就有“MPI_Comm_Self”,即只包含各个进程自己的进程组。而“tag”是用于标识该数据的标签。
很容易看出收发组件的参数稍有差异,MPI_Recv多了一项“status”,而且还是MPI派生的数据类型。字面意思不难理解,好比我们在现实生活中收到邮件先签名确认接收无误,这个聚合类型的“status”主要包含了所接收信息的标识(发送该信息进程的ID,该信息的标签以及长度),以确保两进程间准确的信息收发。
| MPI Datatype | C/C++ | Fortran |
|---|---|---|
| MPI_SHORT | short int | Integer(Selected_Int_Kind(4)) |
| MPI_INT | int | Integer(Selected_Int_Kind(9) |
| MPI_LONG | Long int | Integer(Selected_Int_Kind(9) |
| MPI_LONG_LONG | long long int | Integer(Selected_Int_Kind(15)) |
| MPI_FLOAT | float | Real(Selected_Int_Kind(9)) |
| MPI_DOUBLE | double | Real(Selected_Ind_Kind(15) |
实际上,我们可以用另外两个组件获得”status”信息:
1 | |
实例
以下是实现进程1和0之间的通信:
1 | |
Python实现MPI是借助mpi4py这个宏包,作为脚本型语言,省去了在C和Fortran中的一些参数,形式上更为简洁,将作为以下主要的实例演示。
组通信(collective communication)
组通信是实现一个communicator中所有进程间通信的概念。
对齐各进程时间点和一多广播:Barrier&Bcast
组通信实现的前提是各进程时间点的对齐,实现同步(即synchronization, syn-这个词缀有共同的意思,chon=time,chronic就是慢性的长期的意思),MPI_Barrier这个组件可以实现全部进程同步,语法是
1 | |
实现的过程在MPI教程里有详细描述,原理顾名思义就是在固定一个时间点,在该时间点设置一个阻碍,并作用于通信域中每一个进程。下面组通信的所有组件都是默认所有进程是时间同步的,也就是组件本身具有实现Barrier的功能。
实现进程同步之后,我们便可以通过并行的思路实现数据的群发,也就是所谓的广播(broadcast),这就涉及MPI_Bcast这个组件的功能。
C的版本:
1 | |
主要的参数与上面的点对点通信组件类似,这里不多解释。
python实现的例子:
1 | |
散发(Scatter)和收集(Gather)
MPI散发和收集信息的组件基本上可以满足很大一部分科学计算并行处理的要求,二者实现了全部进程间不同数据的接收和发送。
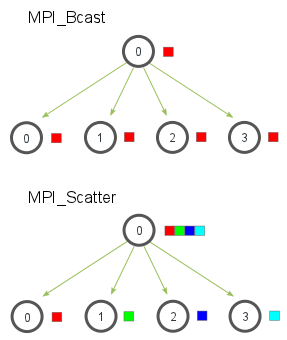
上图可以看出,Bcast和Scatter实现信息发送的形式是一致的,只不过前者实现的同一数据的分发,相当于把根进程的一个数据copy给所有进程,而后者实现了把不同数据分别派发给对应进程的功能,这在实际应用中非常有意义。实际上,在科学计算中就是需要把一个大型任务拆解为很多细小的部分,分而治之,这符合并行编程的基本思路。故而,MPI散发和收集组件有重要的应用场景。
Scatter的作用是一个具体的进程向全部进程派发不同的数据,那么Gather就是从全部进程中收集它们各自不同的数据,是Scatter的逆过程,如下图。
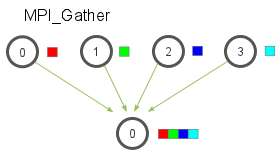
这两个组件的基本接口:
1 | |
相较于Bcast,函数参数明显增加。因为涉及向不同进程分发不同数据或者从不同进程接收不同数据的过程,所以这里需要逐个定义分发和接收数据的数据类型(send_datatype&recv_daratype)以及数量(send_count&recv_count)。而指定根进程(root)以及通信域(communicator)则与之前的组件相同。
另外,Gather还有一个升级版本Allgather:
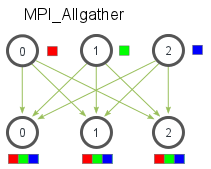
相当于所有进程都执行了Gather的操作,收集其他进程上不同的数据,实现的效果相当于把原先Gather在根进程收集的数据copy到了所有进程中。它的输入参数除了不用指定根进程,其他与Gather是相同的:
1 | |
实例
MPI_Scatter:
1 | |
MPI_Gather:
1 | |
MPI_Allgather:
1 | |
注意,Scatter和Gather在mpi4py中的参数相较于C省略了很多,不过基本的实现方式都是相同的。而且从gather的实现过程中可以看出,python中无需定义额外定义根进程的一维数组“data”,这是脚本语言相当方便的地方。
规约(Reduce)
规约的功能实际上是Gather的结合再升级,升级的内容就是对从不同进程中收集的数据施加一个额外的操作(MPI_Op, Op是operation的缩写)。实现的过程如下:
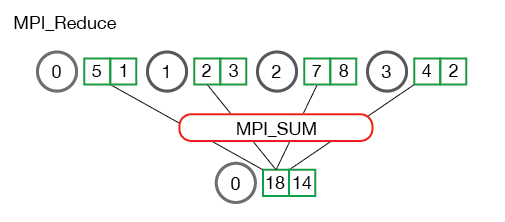
规约的语法如下:
1 | |
它仅比Gather多了一个参数MPI_Op,这里给出MPI_Op常用的几种操作,如下表:
| name | function |
|---|---|
| MPI_MAX | 返回最大值 |
| MPI_MIN | 返回最小值 |
| MPI_SUM | 对所有元素求和 |
| MPI_PROD | 所有元素相乘 |
| MPI_LAND | 跨元素执行逻辑“and”(LAND是logical and的缩写) |
| MPI_LOR | 跨元素执行逻辑“or”(LOR是logical or的缩写) |
| MPI_BAND | 在元素的位之间执行按位and(BAND是bitwise and的缩写) |
| MPI_BOR | 在元素的位之间执行按位or(BOR是bitwise OR的缩写) |
| MPI_MAXLOC | 返回一个最大值以及最大值所在进程的ID |
| MPI_MINLOC | 返回一个最小值以及最小值所在进程的ID |
实例
以计算$\pi$值为例:
1 | |
群
有了之前点对点通信以及组通信的概念,我们自然会疑问,很多并行计算任务需要协调更多的进程,并不需要像组通信那样每次都涉及全部进程的任务处理,那么这时如果我们所需要的通信域并不包含全部进程,是否有对应的解决方案呢?答案是肯定的,群(groups)的概念就应运而生。
关于群的一个重要的组件是MPI_Comm_split,主要的参数如下:
1 | |
这里“comm”是预先准备要划分的通信域,而“color”则是用于给进程所属子通信域做区分,通俗地讲就是一种颜色对应于一个子通信域,如果“color”的关键字没有定义,即“MPI_UNDEFINED”,则该进程不属于任何通信域。“key”即为子通信域的ID,既然要划分”comm“,就有必要给这些新的通信域一个ID。”key“相当于进程的rank,只不过它作用的对象是”newcomm“,也就是我们划分出来的新的通信域。下图为MPI_Comm_split原理示意图。
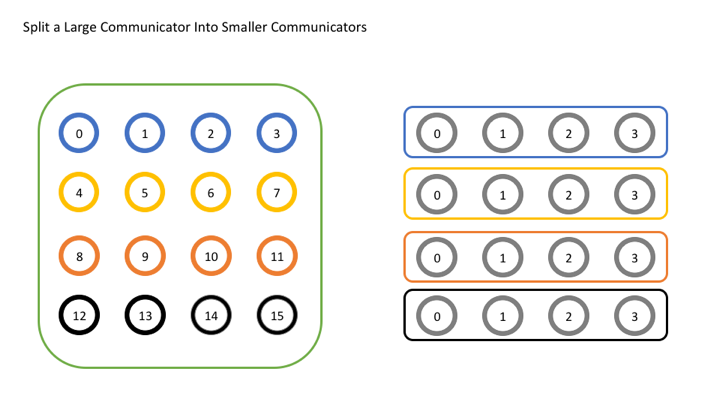
MPI_Comm_split只是创建子通讯域的一个最基本的组件,类似的组件还有MPI_Comm_create
并行编程一些后话
这篇博客的初衷只是解决MPI的概念性问题,了解并行计算的基础原理,实际上MPI作为一种成熟的并行接口协议,有着丰富的组件和功能,本文也是借鉴MPItutorial的做法阐述并行编程对于一些入门者可能存在的误区。总结而言,并行编程的要义就是事无巨细地协调预先建立好的计算机任务进程,从而充分发挥集群多核处理器的计算优势。在实际上编程过程中,只要清楚通信域以及与进程之间的关系,在此基础上便能很轻松地实现简单的并行计算,在超算或者集群中完成PC所不能胜任的计算任务。
Reference
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!